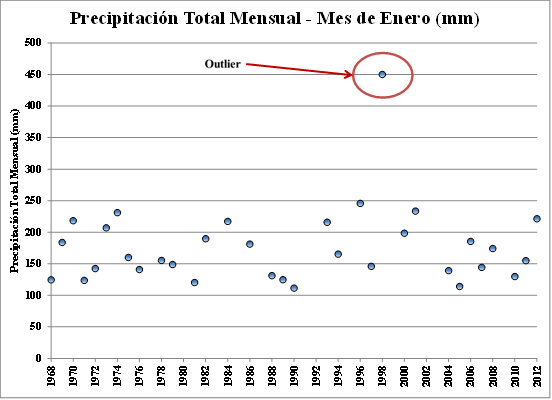
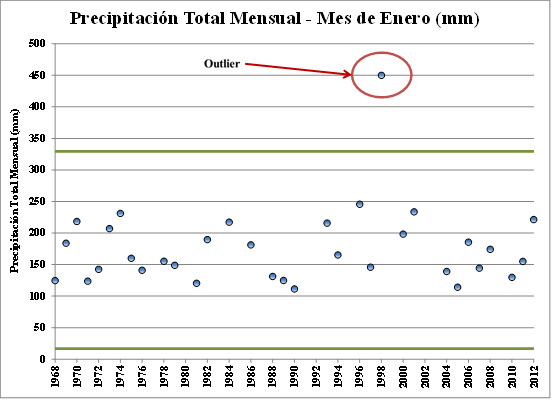
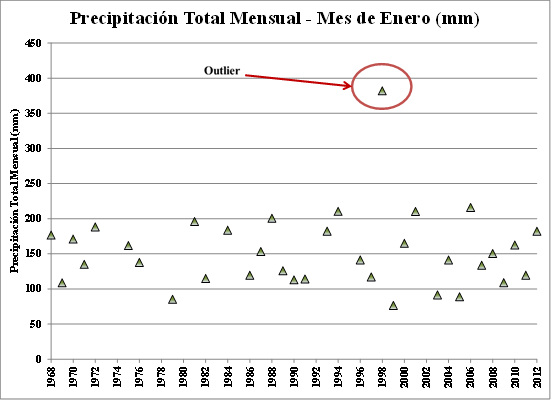
Inicio
Nosotros
Referencias
Documentos
Programas
Manuales
Crecimiento Personal
Contacto
Inicio
Nosotros
Referencias
Documentos
Programas
Manuales
Crecimiento Personal
Contacto